Cut Costs by Querying Snowflake Tables in DuckDB with Apache Arrow

Greybeam's multi-query-engine dream is slowly becoming a reality. Lately, we've been encountering more and more data teams who are looking to offload non-critical workloads to alternative compute engines like DuckDB or DataFusion. More often however, data engineers and data scientists want the ability to execute their workloads locally, without turning on a Snowflake warehouse. But how can we do it?
In our previous post, we covered how to query Snowflake managed Iceberg tables from DuckDB. But what if your company hasn't adopted Iceberg yet? The answer is Arrow Database Connectivity (ADBC).
What is Apache Arrow and ADBC?
Apache Arrow is a columnar memory format designed for fast analytics and data transfer between systems. While Arrow itself is the format specification, ADBC (Arrow Database Connectivity) is the database connectivity layer that enables standardized access to databases using Arrow.
Why Arrow Matters for Analytics
Let's compare two approaches to moving data between Snowflake and DuckDB–the classic ODBC and ADBC.
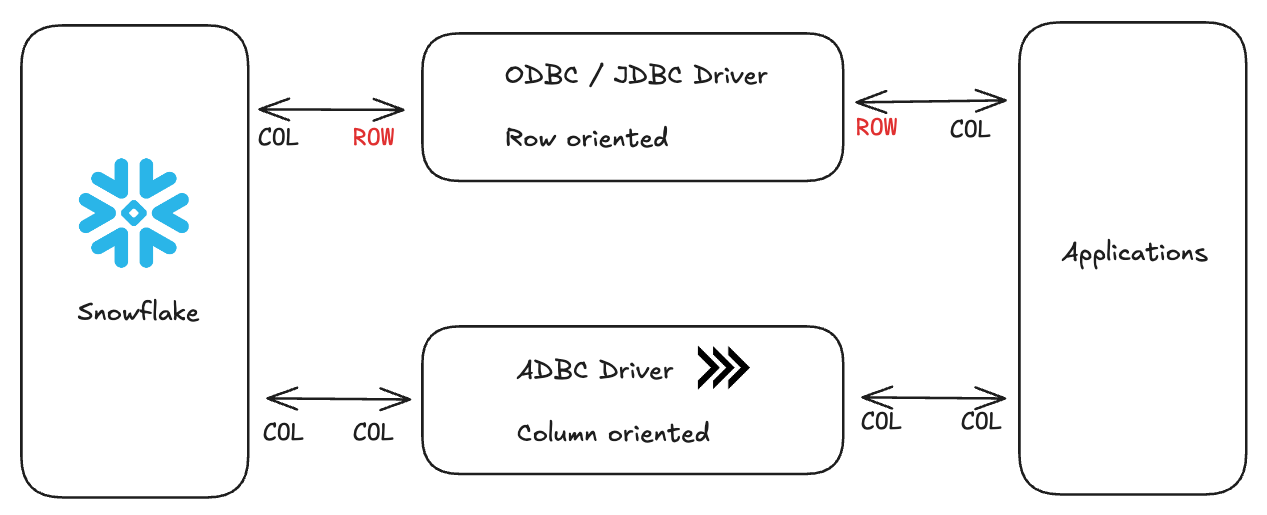
For example, when fetching a 1GB table:
In ODBC land, we hit the Snowflake API with an ODBC driver, Snowflake converts the requested data from columnar format to row format for ODBC (500ms), network transfer (1-2 seconds), deserialize from ODBC (~500ms) to convert the data back from row format into columnar format for DuckDB.
In the great land of ADBC, we hit the Snowflake API with an ADBC driver, the data stays in columnar format, network transfer (1-2 seconds), and we read the data into DuckDB as is.
The challenge in using JDBC or ODBC is due to the rise in columnar databases (Redshift, BigQuery, Snowflake, Databricks, etc.) and columnar formats (Parquet, Avro, ORC, etc.). Using ODBC with columnar databases forces a time-consuming conversion between rows and columns, a process known as serialization/deserialization.
According to DuckDB's benchmarks, ABDC can be up to 38x faster than ODBC for data transfers.
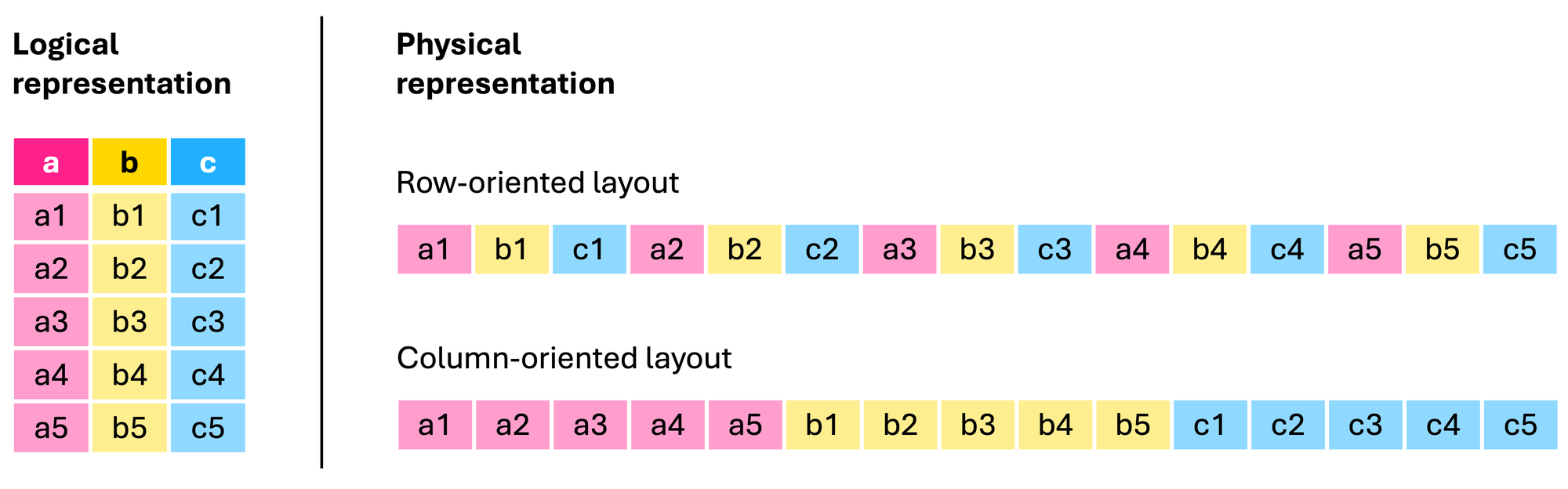
Think about it: when both your source and target databases store data in columns, why convert it to rows during transfer? That's exactly what traditional methods do – they transpose data from columns to rows, then back to columns again. It's like translating a book from English to Spanish and back to English. By keeping the data in columnar format throughout the journey, we eliminate these conversion steps entirely. More on advantages of Arrow here.
Connecting to Snowflake with ADBC
Let's get to the reason we're all here. Admittedly, figuring out the connection params using a private key was a nightmare. Either the docs aren't great or I'm an idiot, so hopefully I've saved you a couple hours of frustration. I've included all of the relevant code in the Github repo here and a full snippet at the end of this blog.
First, install the required libraries:
pip install adbc_driver_snowflake pyarrow duckdbConnection Setup
Establish a connection to Snowflake using the following function:
SNOWFLAKE_CONFIG = {
'adbc.snowflake.sql.account': os.getenv('SNOWFLAKE_ACCOUNT'),
'adbc.snowflake.sql.warehouse': os.getenv('SNOWFLAKE_WAREHOUSE'),
'adbc.snowflake.sql.role': os.getenv('SNOWFLAKE_ROLE'),
'adbc.snowflake.sql.database': os.getenv('SNOWFLAKE_DATABASE'),
'username': os.getenv('SNOWFLAKE_USER'),
'password': os.getenv('SNOWFLAKE_PASSWORD'), # Comment this line if you want to use a password
# 'adbc.snowflake.sql.client_option.jwt_private_key_pkcs8_value': pem_key, # Uncomment this line if you want to use a password
# 'adbc.snowflake.sql.auth_type': 'auth_jwt' # Uncomment this line if you want to use a password
}Now, if you plan on using a private key (which we definitely recommend), you'll need to re-encode it into the PEM format. This requires another library:
pip install cryptographyOnce that's installed, use this function to re-encode your private key.
from cryptography.hazmat.primitives import serialization
def read_private_key(private_key_path: str, private_key_passphrase: str = None) -> str:
"""Read a private key file and return its PEM representation as a string"""
with open(private_key_path, 'rb') as key_file:
private_key = serialization.load_pem_private_key(
key_file.read(),
password=private_key_passphrase.encode() if private_key_passphrase else None
)
# Convert to PEM format with PKCS8
pem_key = private_key.private_bytes(
encoding=serialization.Encoding.PEM,
format=serialization.PrivateFormat.PKCS8,
encryption_algorithm=serialization.NoEncryption()
)
return pem_key.decode('utf-8')Finally, call that function in your main script (full code snippet is at the end of this blog).
pem_key = read_private_key(os.getenv('SNOWFLAKE_PRIVATE_KEY_PATH'), os.getenv('SNOWFLAKE_PRIVATE_KEY_PASSPHRASE'))Materializing the Data in a Local DuckDB Database
Once we have our Snowflake connection, we can fetch data using Arrow and store it locally in DuckDB.
snowflake_cursor = snowflake_conn.cursor()
query = """
SELECT
*
FROM SANDBOX_DB.KYLE_SCHEMA.RAW_ORDERS
"""
snowflake_cursor.execute(query)
# Store results as an arrow table
arrow_table = snowflake_cursor.fetch_arrow_table()
# Create DuckDB connection and store locally to path
duckdb_conn = duckdb.connect('demo.db')
# Store arrow table in DuckDB
table_name = 'raw_orders'
query = f"""
CREATE TABLE IF NOT EXISTS {table_name} AS SELECT * FROM arrow_table
"""
duckdb_conn.execute(query)
# Alternatively you can use the from_arrow_table method
# duckdb_conn.from_arrow_table(arrow_table)Query Away in DuckDB!
All that's left is to boot up DuckDB in our CLI and start querying away. In our previous post we describe how to improve the quality of life when querying in the DuckDB CLI–be sure to check it out!
Full Code Snippet
The entire codebase is available here.
import adbc_driver_snowflake.dbapi
import duckdb
import dotenv
import os
from read_private_key import read_private_key # Uncomment if you're using a private key
# Load environment variables
dotenv.load_dotenv()
# Configuration for Snowflake connection
pem_key = read_private_key(os.getenv('SNOWFLAKE_PRIVATE_KEY_PATH'), os.getenv('SNOWFLAKE_PRIVATE_KEY_PASSPHRASE'))
SNOWFLAKE_CONFIG = {
'adbc.snowflake.sql.account': os.getenv('SNOWFLAKE_ACCOUNT'),
'adbc.snowflake.sql.warehouse': os.getenv('SNOWFLAKE_WAREHOUSE'),
'adbc.snowflake.sql.role': os.getenv('SNOWFLAKE_ROLE'),
'adbc.snowflake.sql.database': os.getenv('SNOWFLAKE_DATABASE'),
'username': os.getenv('SNOWFLAKE_USER'),
'password': os.getenv('SNOWFLAKE_PASSWORD'), # Comment this line if you want to use a password
# 'adbc.snowflake.sql.client_option.jwt_private_key_pkcs8_value': pem_key, # Uncomment this line if you want to use a password
# 'adbc.snowflake.sql.auth_type': 'auth_jwt' # Uncomment this line if you want to use a password
}
# Create Snowflake connection
snowflake_conn = adbc_driver_snowflake.dbapi.connect(
db_kwargs={**SNOWFLAKE_CONFIG}
)
print("Connection to Snowflake successful.")
snowflake_cursor = snowflake_conn.cursor()
# Query Snowflake
query = """
SELECT
*
FROM SANDBOX_DB.KYLE_SCHEMA.RAW_ORDERS
"""
snowflake_cursor.execute(query)
print("Query executed successfully.")
# Store results as an arrow table
arrow_table = snowflake_cursor.fetch_arrow_table()
# Create DuckDB connection and store locally to path
duckdb_conn = duckdb.connect('demo.db')
# Store arrow table in DuckDB
table_name = 'raw_orders'
query = f"""
CREATE TABLE IF NOT EXISTS {table_name} AS SELECT * FROM arrow_table
"""
duckdb_conn.execute(query)
print("Table created in DuckDB successfully.")
# Alternatively you can use the from_arrow_table method
# duckdb_conn.from_arrow_table(arrow_table)
# Close connections
snowflake_cursor.close()
snowflake_conn.close()
duckdb_conn.close()
print("All done :)")
# Now we can spin up DuckDB CLI and work with the data locally! Enter the following command in your terminal to connect:
# duckdb demo.db



Comments ()